
Making S3 more resilient using Lambda@Edge

Do you remember what you were doing on February 28, 2017?
I know where I was: in a war room, frantically trying to figure out how to deal with an S3 outage that hit the us-east-1 region. At the time, I was at a company whose main service depended on files stored in S3 — in us-east-1, where all their infrastructure was located. They had a copy of the S3 bucket in a different region as a backup, but there was no easy way for their infrastructure to access it. Initially, we hoped the incident will blow over quickly, but the outage lasted almost four hours. That’s an entire month’s error budget if you want 99.9% availability.
The S3 outage was a serious event, bringing down many major sites and causing several hundred millions of dollars in damage globally. Mainstream news outlets reported on it. It was a wake-up call for the industry — in case of a major regional outage in the cloud, you want to be in a position where you can do something about it.
Why multi-region active-active delivery matters
At Contentful, we store structured content and serve it via a fast and highly available delivery API. Our clients include large enterprises and Fortune 500 companies, who trust us enough to build their revenue generating sites on the platform we provide. To earn this trust, we offer contractual SLAs on the availability of our APIs.
As an infrastructure engineer working for Contentful, I’m responsible for operating the platform these API services run on. We wanted to make our APIs resilient to regional outages to increase availability, so our team set out to implement multi-region active-active file delivery on S3.
Why multi-region? Regions are the limits of the blast radiuses for big outages. Availability zones are also outage limits — one size smaller than regions. But cloud providers usually offer multi-AZ support for their services out of the box, so most setups are resilient to outages of one single AZ. The next blast limit is the region limit, so it’s sensible to have infrastructure in multiple regions. But to have infrastructure in multiple regions, and to get it to cooperate and cluster, takes work.
The next question is, why active-active? Why isn’t failover not enough?
Imagine you have a failover solution, and the primary region fails. You probably have some kind of health check that detects this failure, maybe after two bad signals, to make sure that it’s not picking up just noise or internet weather. Then it initiates the failover solution, some signals pass between some systems (for example an SNS message triggering a lambda) and finally a routing change. Even if fully automated, all of these need some time to propagate, and likely take longer than the approximately four minutes that you have if you’re aiming for 99.99% availability. Finally, when the incident is over, you’ll likely have to switch back manually. Failover systems are not blue/green deployment systems — the backends are not symmetrical and the switch is optimized and automated in one direction only.
Even with this, if you have a simple backend like S3, this might be good enough. But with more complex backends, such as services running on Kubernetes or on EC2 nodes in an autoscaling group, there are other difficulties.
Regional outages are not so common, so a failover only occurs very rarely. In the meantime, you have two different instances of your stack that you’re trying to maintain on the same architecture but with a different load and traffic. This creates room for errors, such as something being deployed only to the primary region and then going unnoticed because there’s no traffic on the failover. Or the failover infrastructure simply can’t scale up fast enough when traffic hits. To make sure the failover works, you need to run regular tests and drills — everyone’s favorite pastime.
Active-active has multiple advantages over failover: adjustments are faster, it works more reliably and it’s easier to maintain. You always have a signal on the health of both backends, and you don’t need to scale from 0 to 100 in a few minutes.
Technical implementation of multi-region active-active on S3
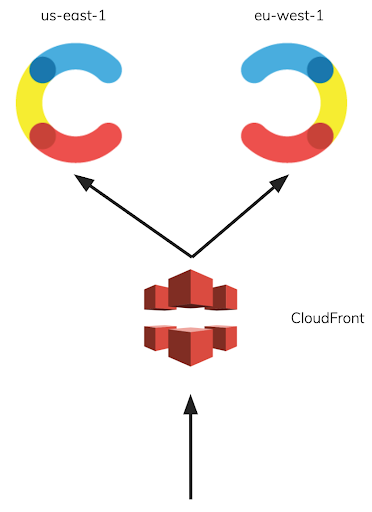
The part of the Contentful API that serves the images, files and other assets in the content is based on S3’s file service. To serve files from S3, we use a very standard setup: a CloudFront distribution with an S3 backend to serve as CDN. This is how the asset delivery infrastructure looked roughly a year ago:
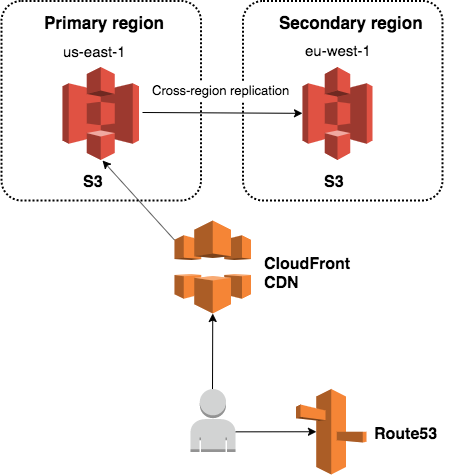
A request goes to Route53 to resolve the URL of a CloudFront distribution in front of S3 in us-east-1. The bucket in S3 is replicated to us-west-2.
We didn’t want to overhaul the whole thing — we wanted to extend this to be multi-region active-active. One easy solution would be a round robin using a weighted DNS entry as a backend for CloudFront:
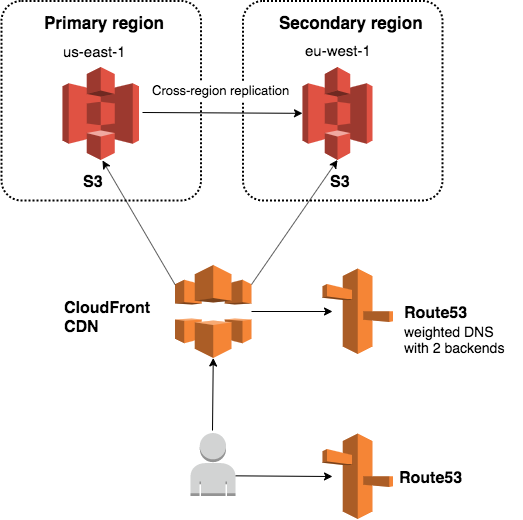
For this, we would place a weighted DNS entry in Route53 that resolves to each of the buckets with 50-50 weight; if Cloudfront uses this entry as a backend, the requests would end up in both buckets with 50-50% chance.
Unfortunately this doesn’t work due to a security limitation in S3 — as a file server, it will only serve requests that have the exact bucket name and region in the host header. And since neither the bucket name nor the region are the same for the original bucket and the replica (bucket names need to be globally unique), the same request cannot be valid for two buckets. With this solution, half the requests would fail. Not good.
But we know exactly what’s wrong — the request header. Once we know where to send the request, can’t we just fix the header? Is there a way we can change it on the fly?
Using Lambda@Edge to modify requests
There is a way to inject some logic into CloudFront and modify the request! This mechanism is called Lambda@Edge, a lambda function that is attached to the CloudFront distribution and can be used to modify the requests and responses in any way we want. In this case, it’s very simple: just rewrite the host header in the request.
All we need to do is get the information on where to send the request, which we can uncover by doing a DNS resolution in Route53 (for the DNS entry with the weighted backends). It returns an address (either of the two buckets), we update the host header in the request with that information and then send the request to the right backend. This way, one CloudFront distribution can have both S3 buckets as origin servers. The idea came from this article, where they used the same logic to modify requests to implement AB testing.
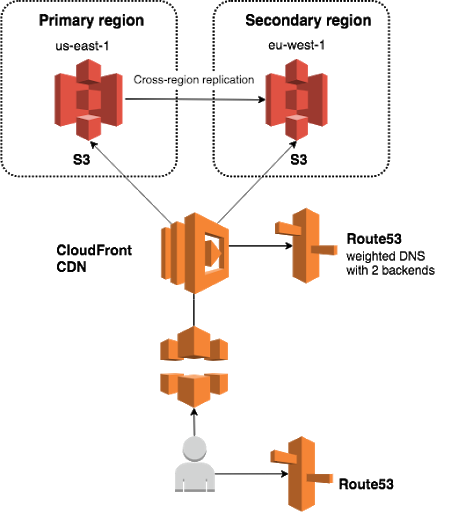
When does this lambda run exactly? CloudFront actually allows you to inject lambdas at four points on the path: once, as the request comes in; once, for uncached requests, just before the request is sent back to the origin server; and again at the same points for the response. To get this behavior, our lambda is injected at the origin request:
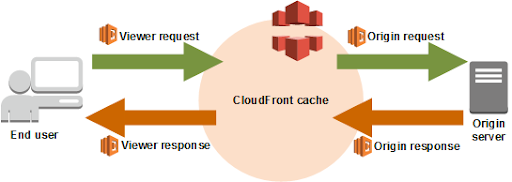
We tried it, implemented it, and built a small POC. But how can we tell which region was a request served from? We had no such information in the response (for example a custom header). To differentiate between responses from the two regions, we uploaded two different versions of the same image to the original bucket and the replica under the same name, and voilà — as we made repeated requests, we saw the two images alternating (with about 50-50%) in our browser.

In the end it was only 20 lines of code, hardly more than a custom CloudFront configuration. It felt like writing nginx config.
The risks of the Lambda@edge solution
At this point, it was just a technical solution — not a production-ready, reliable and resilient component.
This is edge computing. It comes with all the risks of edge computing. For me, the biggest risk is that there’s nothing between the user and the service — there is no way to route traffic around it. If the service fails for any reason (more likely a programming error than, say, resource starvation), there is no way to divert traffic around the service. Of course, every system has an edge, but in our implementation, the API is directly on it. Also Lambda@Edge (and Lambda in general) was new to our stack. We didn’t know how it behaves or how it fails, and we had no automation around it.
All in all, there was a lot of risk around this solution, which gave us pause. Our goal was to increase availability, which is not quite achieved by introducing a system that increases the probability of causing an outage ourselves. We needed to manage this risk, and to reduce it to an acceptable level.
We wanted to use multi-region active-active delivery to increase availability, but high availability isn’t achieved by introducing a system with a higher probability of causing an outage on our end.
A few things were obviously problematic with the Lambda@Edge-based solution. It wasn’t wrong. It just had some challenges that we needed to solve:
1. Bare bones code deployment
AWS offers a web-based editor for the Lambda code with minimal syntax highlighting. When you save the code with a save button, it’s deployed. The whole thing feels like writing Yahoo mail online around 1996, except it changes the configuration at the edge of your infrastructure and, if you made a mistake, your whole site is down for everyone. We needed to create deployment automation.
2. Javascript
The code needed to be in JavaScript. Although JS is a part of our standard stack, we felt we needed a bit more confidence in writing it. Even while implementing the proof of concept, we realized that the code was very wasteful because it repeated the same DNS request over and over. For a round-robin effect, we could reuse some results if we cached it, but that’s more complex code and moves out of the realm of stateless config.
3. Lack of production experience
Before this, we didn’t have production experience with Lambda. We didn’t have any experience with error states or action options.
4. Computing on the edge
One factor that increased all these risks: there was no way to route traffic around the service in case of failure; there was nothing between the user and the service. If someone made a small programming error, the request would invariably fail, and since it comes from the user, there was no retry we could implement. Every system has an edge, but in our case, the API was directly on it. A typo would cause a full outage. We needed to understand how to manage this characteristic.
This API is on the critical path. We have contractual SLAs, and there’s no point in raising availability a little while increasing the risk of a complete outage by a lot. But how could we do better? How could we map out what needs to be done to manage those risks, and how would we know when it’s good enough?
Why gut feelings matter
Since we had no better metric, we decided to make it our goal to raise confidence. To engineers this might sound… quite unscientific, right? To base our decisions on gut feelings, and feelings of confidence? This isn’t how engineering should work!
Here’s how I see it: we felt that something was off, and this is a valuable signal. It’s a familiar feeling: something seems amiss, and then you realize that the weight of the phone in your jeans pocket was what was missing. Some of the things you do become muscle memory.

I feel like I'm forgetting something.
As the infrastructure engineers, we have years of experience operating these kinds of systems. We develop gut feelings about them. It may not be much, but it’s better than not having a signal at all. So we set out to turn our gut feelings into actionable tasks, and improve things little by little until we felt confident.
It proved to be a good starting point because it presented the following question: What would make us feel more confident? We reformulated it as a question that’s easier to answer: what gives us trust in our current software platform?
Logging, monitoring, CI, CD, and alerting
Tooling for development and deployment
Version control and tests for code and config
Understanding performance, dependencies, risk matrix
This step made it obvious that there was a bunch of tooling we could build; the question was now, what do we choose to build and how do we make sure we’re not overlooking something important?
Production readiness criteria lists
I’m the kind of person who deals with the chaos of the universe by writing elaborate lists, so I suggested that we visualize success by writing down how things would work if they worked well — if they felt the same way our current production systems feel while we operate them. We created a production readiness criteria list.

Lists like these exist for services in a microservices-based architecture. There are books, talks and articles on this. We haven’t found a resource for infrastructure elements, probably because they are quite different in this regard from a service.
First, we wrote our requirements on an abstract level. We imagined that someone gave us a new infrastructure component in a black box that will be added to our existing infrastructure. What does it need to make us feel confident and familiar in operating it, or even to be on call for emergencies? For example (in no particular order):
How is it monitored?
How is it deployed?
How should it scale?
How can I change its configuration?
How can we tweak it during an incident?
What does it do if one of its dependencies fails?
What happens if the component itself fails?
What kind of metrics do we want to have?
We made a list of all of these, and then grouped them by topic. The list ended up being some 70 items long, covering everything from code ownership to security criteria. Then we took this abstract list and translated the requirements to the current solution. We didn’t just evaluate Lambda@Edge in general but this specific case. This was important because risk is extremely dependent on context.
After a few more iterations, we had a specific and detailed list. This basically gave us a gap report between the current and the ideal state. But building wasn’t the next step.
We remembered that our production readiness criteria list was an ideal, a menu to pick and choose from. We needed to pick enough items to bring our confidence up to an acceptable level. So for each item in the list, we carefully considered risk, cost and benefit. We marked what we wanted to build, what was already done, and what we would not build.
For example, having logs was one abstract requirement. Most of our app logs are in Splunk. For this specific case, do we want the logs in Splunk, or is having them in CloudWatch enough for our needs?
We documented all these decisions, especially the ones we decided not to pursue. It was an exercise in risk management informed by our gut feelings. I think it’s actually fine to take informed risks and make calculated bets, but you need to be aware and explicit about them so that it’s easy to revisit the choices that didn’t work out, or if circumstances change.
Building out Lambda@Edge as a platform
As we were doing all of this, we actually built enough tooling for Lambda@Edge that we turned it into a reliable software platform. One where you can run things with more complicated logic than just adjusting request headers.
This brings us back to the other problem we needed to solve: our uncertainty about the language used in Lambda@Edge, namely JavaScript. At the time, it seemed like we didn’t really have a choice in the matter; it was the only language Lambda@Edge supported at the time (now you can also opt for Python). Since it’s a script language, it’s hard to catch even simple errors, like type mismatches during development. It’s just too risky.The chance of human error increases at least linearly with the lines of code needed.
Someone suggested that we use TypeScript, which is a strongly-typed language that can be transpiled to standard JavaScript. Even though TypeScript was a new language for our team, it allowed us to avoid many programming mistakes and produce high quality code.
JavaScript:
TypeScript:
We found an existing TypeScript library with the needed AWS CloudFront components. The specific events we wanted to handle were missing, so we ended up contributing to the library.
While working on our specialized production readiness criteria list, we realized that we were missing something that has a big impact on our confidence but isn’t a characteristic of the system: operational experience.
Operational experience is a collection of experiences:
Having the right alerts, dashboards and runbook
Having a sense of the possible error states,
Knowing where to look when there’s a problem
Knowing what options you have for action.
It’s about being familiar enough with the area to be creative. This experience is not something you get by waiting around until all this accumulates. You can take an active approach and run some simple drills on operations that you think you’ll need. Realizing we lacked enough operational experience, we started to actively work towards getting more before we moved critical components to the new platform. By the time we finished, we felt confident to safely release our code to production.
Life on the edge
Today we heavily rely on Lambda@Edge as a software platform. We have mission-critical, customer-facing business logic running on it that’s being actively developed.
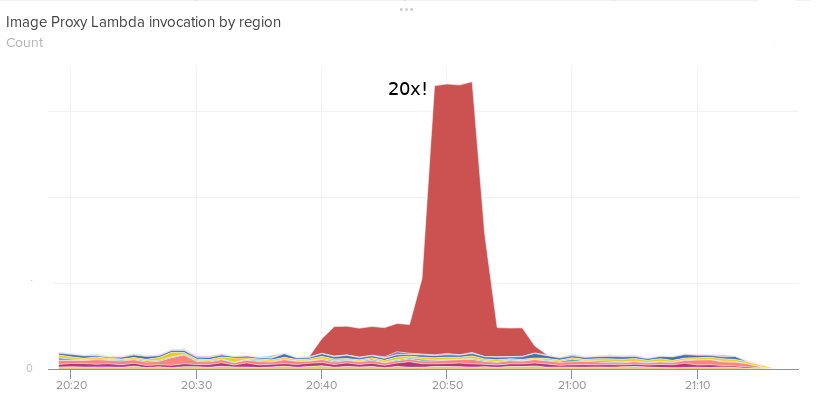
So what’s it like, life with Lambda@Edge? First of all, it scales like a dream. The Lambdas can take a 20x traffic spike without a hiccup. It’s also cost-effective: the Lambda functions finish in just a few milliseconds. That’s quite far from AWS’s minimum billable unit, which is 50 milliseconds. Also, since this code itself runs in CloudFront, which is a global service, it’s immune to regional outages.
There are some downsides of course. We learned that it's harder to extensively test code before running it on Lambda@Edge, because you can’t emulate the full environment. You can do some unit tests in a CI, but you need dedicated testing environments for integration tests.
If you want to treat Lambda@Edge as a software platform, you need to deploy it as you deploy software. We still deploy Lambda as infrastructure configuration because, when we started out, the first 20 lines of code felt more like configuration. But we might change this soon. Infrastructure and software changes at different paces, and they need different deployment pipelines with different characteristics.
Finally, when we needed to look into the logs to investigate a problem, we realized that they weren’t easy to find. Because CloudFront is a global service, CloudWatch collects logs in each region based on the origin of the request. This means that the logs for a given request will be in the AWS region closest to the sender and are a bit hard to find at times.
Summary
Starting from our routing problem, we turned Lambda@Edge into a reliable software platform. Creating the traffic manipulation logic was the smaller part of the task, but getting to a state where CloudFront with Lambda@Edge was a reliable platform in our stack required a systematic approach in mapping out what needed to be built to ensure operability. We used our engineering gut feelings to spot the need, and then production readiness criteria lists to build a gap analysis and manage the special risks that edge computing poses.
Using TypeScript and deployment automation removed a lot of the possibility for human error from the system, while purposefully building operational experience ensured we can leverage human knowledge and creativity when needed.
Resources
Original idea
Dynamically route viewer requests to any origin with Lambda@Edge
Amazon S3 region failover part 2: CloudFront S3 origin failover
Failover
Multiregion



