Delivering BBC Online using serverless

Johnathan Ishmael
Lead Technical Architect, Digital Products Group
Tagged with:
A BBC News article powered by serverless.
Previously we wrote about how we’ve moved BBC Online to the cloud. This post looks more closely at why Web Core, our new web technology platform is built using serverless cloud functions.
The BBC has some big traffic days
Before we talk about serverless, here’s some context to the workloads we need our technology platform to handle.
During the 2020 US Election, the BBC News website received visits from over 165 million unique browsers from around the world. During the election week the Web Core stack averaged 80,000 requests per minute, peaking at 120,000 requests per minute to our platform. Those requests are the ones which made it past the traffic management layers (caches) in front of us. At its peak our edge traffic managers and CDNs saw 2.5 million page views per minute (around 41,000 requests per second).
At first glance, our traffic profile is typically cyclical — busy during the day, and quiet overnight. However, it isn’t completely smooth and predictable as the graph below shows. Instead, it fluctuates based on the current news, social media traffic, as well as calls to actions on TV, radio and when we send push notifications to our apps.
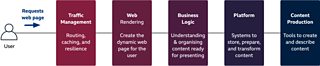
A view of how a request travels through the Web Core Stack
In addition, different parts of BBC Online will peak at different times, and in unpredictable ways. If a major news story breaks, BBC News can peak in an instant. And BBC Bitesize, during the first UK national lockdown, became consistently busy during the school day, as school children moved to learning online.
As an example, let’s take the breaking news story around the London Bridge attack in November 2019. The traffic profile at our edge cache for this page resulted in a 3x increase in traffic in a single minute (4k req/s to 12k req/s) followed by a near-doubling of traffic a few minutes later (12k req/s to 20k req/s).
These key moments are critical for the BBC, and they are the moments in which the audience turn to us. We must not fail. Any technology we choose must be able to respond to these traffic patterns.

A chart showing requests per second over the 7 day period 3/11/2020 to 10/11/202 for bbc.co.uk/news. The traffic is mostly cyclical, with a few exceptions as news stories break.
Choosing the right platform for the job
Choosing the type of compute depends upon factors associated with your workload. These can include the number of requests, duration of work, and resources required (CPU, Memory, Network). Being a website, requests are short lived — up to a second or two — and don’t require persistence between requests. The requests are typically CPU bound, rather than restricted by network or memory.
Virtual machines (e.g. EC2 or Compute Engine) are useful for workloads that change no faster than you’re able to add capacity, or for work loads that can tolerate delay in scaling (e.g. queue based event systems). They are also useful for short lived sessions that can tolerate scale down events. For our use case — rendering web pages — virtual machines don’t tolerate large bursts of traffic well enough, as they can take a few minutes to add capacity. As mentioned previously, our traffic load can double in less than a minute, and so autoscaling might not react quickly enough. Our experience has taught us that we need to over provision the number of instances you have available (e.g. 50% more than what you need) in order to deliver enough capacity to manage scale events. Even trickier is understanding when you have over provisioned and when you should scale down. Virtual machines comes in many different flavours, tailoring for high memory, high CPU or a combination of both. So it’s possible to pick a compute platform that matches your workload, response times and cost profile.
Containers (e.g. a Kubernetes cluster or Fargate) which run on top of fixed compute. Like virtual machines they are useful for traffic volumes which slowly change over time. While you’re able to start up a new container quickly to handle a new session, you’re still limited by the underlying compute instance on which the containers are running. The underlying compute hardware has to scale to meet the demands of the running containers. Containers are great for long lived, stateful sessions, as they can be ported between physical hardware instances while still running. This allows for them to be redistributed across physical hardware as the workload grows and shrinks. A great use case for containers would be an online game, where you need sessions to persist as you reorganise your workloads.
Serverless functions (e.g. Lambda or Cloud Run) are, in essence, containers running on top of physical hardware. They are ideally suited for handling unpredictable traffic volumes and for non-persistent and stateless connections. As a customer of the service we don’t need to worry about how the underlying hardware is provisioned to deal with load. Instead, we simply initiate requests to the service. The burden of provisioning the containers, and scaling of the underlying infrastructure is handled for us by the service provider. So why can they handle the scaling better than we can using containers? — The simple answer is economy of scale, in that the provider manages the work loads of many customers shared across the same physical hardware platform, what is a large increase in workload for us, is small in comparison to the service providers overall workload.
Reducing operational complexity
One of the biggest advantages of serverless over fixed compute is that of reducing the operational complexity of running the service. Reducing the engineering effort in running and maintaining our systems allow us to focus more on the audience product and experiences. The further away you move from the bare bones hardware, the less the engineering cost for the developing team. What used to be engineering effort for DevOps teams, is now commoditised.
With Virtual Machines we need to consider general maintenance and security, everything from patching the underlying operating system through to ensuring we have configured the machine for running at scale (such as available file handlers). We need to ensure the machine is secure from an external attack, whilst being remotely administrable. We also have to manage things such as log rotation and temporary file storage. All of these things go away when you move towards serverless.
Managing the scaling rules of a fixed compute server is complex and requires extensive testing. You have to consider aspects such as measuring your workload, capturing metrics, understanding the correct properties to scale on, and by how much. Understanding and implementing these things come with some considerable effort.
Next time… using serverless in Web Core
This blog post has outlined some of the considerations we took when choosing a technology platform for Web Core.
In my next blog post I’ll talk about how we make use of serverless, including how it fits into our architecture, its performance and some benefits we’ve gained from its use.